架构设计与核心特性
1.逻辑架构
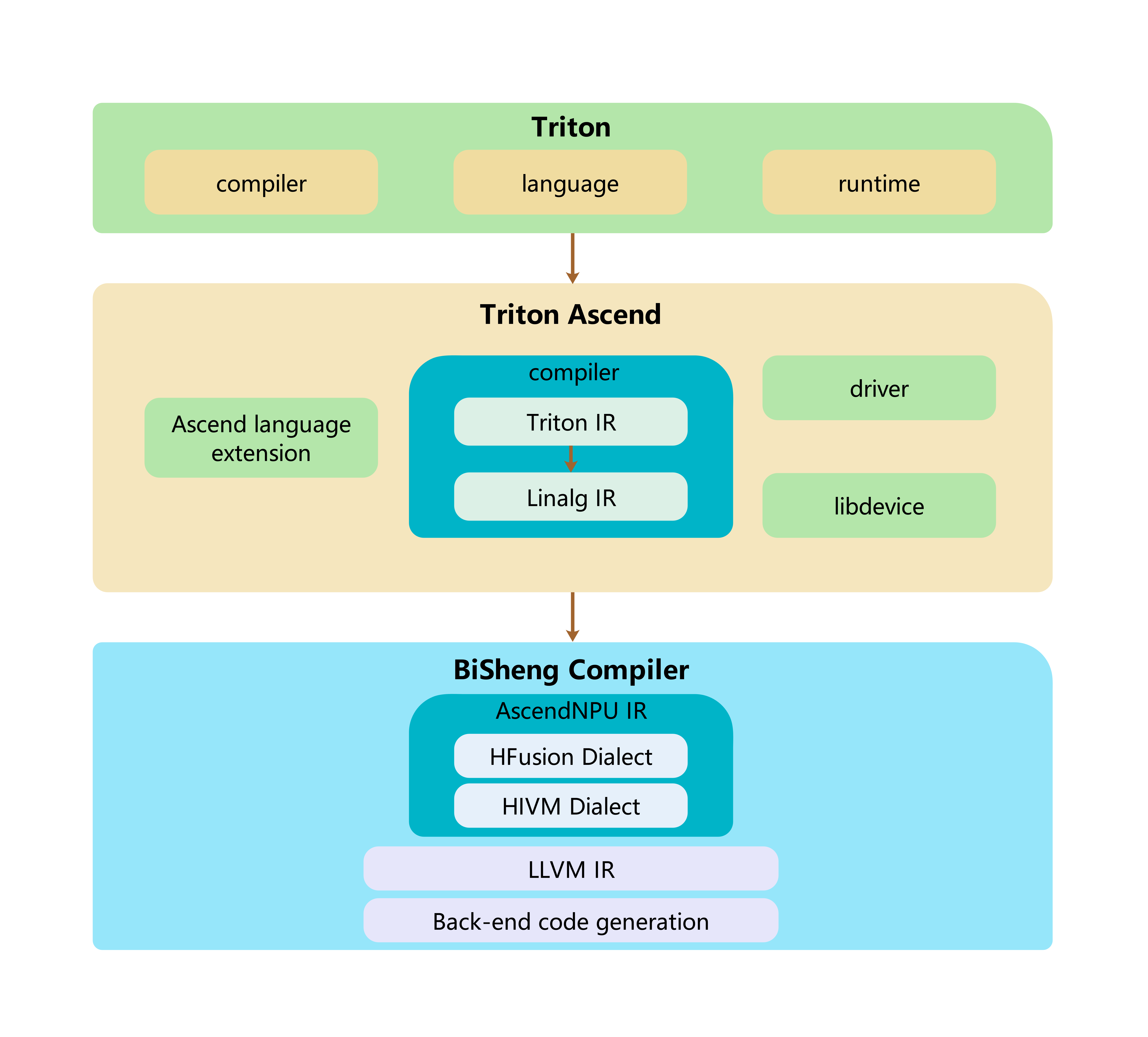 Triton-Ascend 架构说明
Triton-Ascend 架构说明
核心组件:
Ascend language extension:适配 Ascend 的 Triton 语言扩展compiler:适配 Ascend 的 Triton 编译器driver:适配 Ascend 的设备驱动接口
组件功能:
Ascend language extension
在标准 Triton 语言基础上,引入针对 Ascend NPU 架构的语法与语义扩展。compiler
接收来自上层 Triton compiler 生成的中间表示文件TTIR(Triton IR),执行一系列适配昇腾硬件的转换。Triton IR → Linalg IR → AscendNPU IR → triton_xxx_kernel.o
Triton IR 转换为 Linalg IR,再经 BiSheng Compiler 生成面向 Ascend NPU 的可执行二进制文件
triton_xxx_kernel.o。driver
提供 Triton 运行时与 Ascend 软件栈(CANN)之间的对接能力, 加载由 BiSheng Compiler 生成的设备侧可执行内核triton_xxx_kernel.o。
2.代码结构
2.1 代码结构原则
本项目在标准 Triton 基础上,扩展支持华为 Ascend NPU(通过 CANN 软件栈)。整体设计遵循以下代码原则:
若修改与目标硬件无关(target independent),应保留在 Triton core 部分(如language、runtime的通用修改);
若修改与 Ascend 硬件强相关(target affinitive),应放在 Triton-Ascend 中。
2.2 目录结构与功能说明
include/ 和 lib/
内容:包含针对 Ascend NPU 的 MLIR Passes、Dialects(方言)以及相关工具。
作用:用于在 MLIR 编译流程中表达和优化 Ascend 特定的计算图。
libdevice.py
内容:适配 Ascend NPU 的
libdevice接口。作用:提供适配 Ascend NPU 硬件的底层实现支持,供 Triton 算子调用。
backend/compiler.py
内容:
triton-ascend编译器主入口。作用:将 Triton 高层 DSL 代码编译为可在 Ascend NPU 上执行的可执行二进制文件(如
.o文件)。
backend/driver.py
内容:
triton-ascend驱动模块。作用:加载并启动已编译的可执行二进制。
3. Modules
3.1 Triton core Enhancement
3.1.1 Language expansion
序号 |
算子名称 |
描述 |
|---|---|---|
1 |
|
按照指定的偏移量(offsets)、尺寸(sizes)和步幅(strides)参数,将一个张量插入到另一个张量中。 |
2 |
|
按照指定的偏移量(offsets)、尺寸(sizes)和步幅(strides)参数,从另一个张量中提取一个切片张量。 |
3 |
|
读取一个具有维度的张量,并返回指定偏移量处的单个元素。 |
3.2 Triton-Ascend
3.2.1 Compiler Options
序号 |
NPUOptions |
硬件平台 |
用途 |
|---|---|---|---|
1 |
multibuffer |
NPU |
Autotune Option: Enable or disable ping-pong pipeline. |
2 |
enable_auto_bind_sub_block |
NPU |
Autotune option (CV-fused kernels only): Enable or disable auto-binding of sub-blocks. |
3 |
enable_hivm_auto_cv_balance |
NPU |
Autotune option (CV-fused kernels only): Enable or disable automatic CV balancing. |
4 |
sync_solver |
NPU |
Autotune option (CV-fused kernels only): Enable or disable the synchronization solver. |
5 |
unit_flag |
NPU |
Autotune option: Enable or disable the sync unit flag. |
6 |
inject_barrier_all |
NPU |
Autotune option: Enable or disable automatic injection of barriers for all operations. |
7 |
inject_block_all |
NPU |
Autotune option: Enable or disable automatic injection of blocks for all operations. |
8 |
limit_auto_multi_buffer_only_for_local_buffer |
NPU |
Autotune option: Restrict automatic multi-buffering only to local buffers. |
9 |
limit_auto_multi_buffer_of_local_buffer |
NPU |
Autotune option: Enable or disable automatic multi-buffering for local buffers. |
10 |
set_workspace_multibuffer |
NPU |
Autotune option: Enable or disable multi-buffering for the workspace. |
11 |
tile_mix_vector_loop |
NPU |
Autotune option (CV-fused kernels only): Enable or disable tiling for vector loops. |
12 |
tile_mix_cube_loop |
NPU |
Autotune option (CV-fused kernels only): Enable or disable tiling for cube loops. |
13 |
disable_auto_inject_block_sync |
NPU |
Autotune option (CV-fused kernels only): Enable or disable automatic injection of block synchronizations. |
14 |
stream |
NPU |
Optional: Inform the compiler about the NPU stream to use. |
15 |
enable_linearize |
NPU |
Autotune option: Enable or disable the linearization pass. |
16 |
enable_nd2nz_on_vector |
NPU |
Autotune option (CV-fused kernels only): Enable or disable the ND (n-dimensional) to NZ (non-zero) layout transformation. |
17 |
auto_blockify_size |
NPU |
Autotune option: Enable or disable AutoBlockify pass. It is ignored when TRITON_ALL_BLOCKS_PARALLEL is not set |
3.2.2 SIMD compiler
序号 |
Pass |
目的 |
IR 转换 |
|---|---|---|---|
1 |
triton-to-structured |
linearize |
ttir->ttir |
2 |
triton-to-unstructured |
convert indirect axis to loop |
ttir->ttir |
3 |
triton-to-linalg |
memory/reduction/view/creation/math/arith/linear algebra to linalgir |
ttir->linalgir |
4 |
triton-to-other |
ttir->hivm/hfusion/llvm |
ttir->hivm/hfusion/llvm |
3.2.2.1 TritonToStructured
处理指针表达式和mask表达式中的整除取余,通过升维的方法,去除整除取余后重新生成load/store 等OP。
Converter |
功能 |
局限性 |
|---|---|---|
RewriteAddPtrOp |
分析 |
1. 所涉及的原始迭代轴(如 |
CreateAddpr |
根据分析得到的 |
依赖于 |
RewriteLoadOp |
分析 |
1. 所涉及的原始迭代轴(如 |
BuildMask |
根据分析得到的 |
仅处理由 |
CreateLoad |
使用由 |
依赖于 |
RewriteStoreOp |
分析 |
与 |
CreateStore |
使用由 |
依赖于 |
RewriteAtomicRWMOp |
处理原子读写修改操作(如 |
通常继承与 |
RewriteAtomicCASOp |
处理原子比较并交换操作 ( |
|
RewriteWhile |
处理 |
不支持循环体内包含条件分支 ( |
RewriteFor |
处理 |
3.2.2.2 TritonToUnstructured
序号 |
Pass / 转换器 |
描述 |
|---|---|---|
1 |
discrete-mask-access-conversion |
将Triton中基于离散索引掩码(Discrete Mask)的内存访问模式(如 |
2 |
triton-to-unstructured |
将经过 |
3 |
bubble-up-operation |
主要对 |
3.2.2.2.1 discrete-mask-access-conversion
转换器名称 |
描述 |
|---|---|
DiscreteMaskStoreConversion |
首先进行mask分析,如果mask分析结果是非连续的,将原始的store操作转化为以下序列: |
DiscreteMaskLoadConversion |
首先进行mask分析,如果mask分析结果是非连续的,将原始的load操作转化为以下序列: |
DiscreteMaskAtomicAddConversion |
首先进行mask分析,如果mask分析结果是非连续的,将原始的atomic_add操作转化为以下序列: |
3.2.2.2.2 triton-to-unstructured
TritonToUnstructured Converters |
描述 |
|---|---|
UnstructuredMemAccessConverter<triton::LoadOp> |
将LoadOp转化为多重循环标量加载 |
UnstructuredMemAccessConverter<triton::StoreOp> |
将StoreOp转化为多重循环标量存储 |
UnstructuredMemAccessConverter<triton::AtomicRMWOp> |
将AtomicRMWOp转化为多重循环标量Atomic操作 |
UnstructuredMemAccessConverter<triton::AtomicCASOp> |
将AtomicCASOp转化为多重循环标量Atomic操作 |
3.2.2.2.3 bubble-up-operation
转换器名称 |
描述 |
|---|---|
BubbleUpExtract<tensor::ExtractOp> |
extract op顺序上移优化,在某些场景可以避免产生不必要的循环 |
BubbleUpExtract<tensor::ExtractSliceOp> |
extract op/extract_slice顺序上移优化,在某些场景可以避免产生不必要的循环 |
3.2.2.3 TritonToLinalg
3.2.2.3.1 triton-to-linalg
TritonToLinalg converts ttir to linalg ir.
Converter |
描述 |
|---|---|
StoreConverter |
triton::StoreOp to memref::copy |
AddPtrConverter |
triton::AddPtrOp to memref::ReinterpretCast |
GetProgramIDConverter |
triton::GetProgramIdOp to a param in functionOp |
GetNumProgramsConverter |
triton::GetNumProgramsOp to a param in functionOp |
LoadConverter |
triton::LoadOp to memref::copy and bufferization::ToTensorOp |
AtomicRMWConverter |
triton::AtomicRMWOp to linalg::GenericOp |
AtomicCASConverter |
triton::AtomicCASOp to linalg::GenericOp |
MakeRangeConverter |
triton::MakeRangeOp to linalg::GenericOp |
SplatConverter |
triton::SplatOp to linalg::FillOp |
ClampFConverter |
triton::ClampFOp to tensor::EmptyOp, linalg::FillOp |
PreciseDivConverter |
triton::PreciseDivFOp to arith::DivFOp |
ArgMinConverter |
triton::ArgMinOp to linalg::ReduceOp |
ArgMaxConverter |
triton::ArgMaxOp to linalg::ReduceOp |
ReduceConverter |
triton::ReduceOp to linalg::ReduceOp |
ScanConverter |
triton::ScanOp to func::CallOp |
ReshapeConverter |
triton::ReshapeOp to tensor::ReshapeOp |
ExpandDimsConverter |
triton::ExpandDimsOp to tensor::ExpandShapeOp |
BroadcastConverter |
triton::BroadcastOp to linalg::BroadcastOp |
DenseConstantConverter |
arith::ConstantOp to linalg::FillOp |
ExternElementwiseClOpConverter |
triton::ExternElementwiseOp to linalg::MapOp |
TritonMulhiuiConverter |
triton::MulhiUIOp to arith::MulSIExtendedOp |
TritonPreciseSqrtConverter |
triton::PreciseSqrtOp to math::SqrtOp |
AdvanceConverter |
triton::AdvanceOp to memref::ReinterpretCastOp |
TransposeConverter |
triton::TransOp to linalg::TransposeOp |
SplitConverter |
triton::SplitOp to tensor::ExtractSliceOp |
JoinConverter |
triton::JoinOp to tensor::InsertSliceOp |
CatConverter |
triton::CatOp to tensor::InsertSliceOp |
BitcastConverter |
triton::BitcastOp to arith::BitcastOp |
LoopConverter<scf::ForOp> |
scf::ForOp to scf::ForOp |
LoopConverter<scf::WhileOp> |
scf::WhileOp to scf::WhileOp |
YieldConverter |
scf::YieldOp to scf::YieldOp |
GatherConverter |
triton::GatherOp to func::FuncOp |
GatherLoadConverter |
triton::GatherLoadOp to scf::ForOp |
DeviceAssertConverter |
triton::AssertOp to func::FuncOp |
DevicePrintConverter |
triton::PrintOp to func::FuncOp |
MatmulConverter |
triton::DotOp to linalg::MatmulOp |
SortOpConverter |
triton::SortOp to func::FuncOp |
DotScaledConverter |
triton::DotScaledOp to linalg::MatmulOp |
PtrToIntConverter |
triton::PtrToIntOp |
MakeTensorPtrConverter |
triton::PtrToIntOp to arith::IndexCastOp |
3.2.2.4 other passes
Pass名称 |
功能描述 |
核心转换器 |
转换器描述 |
|---|---|---|---|
triton-to-annotation |
处理Ascend NPU特有的编译提示指令 ( |
TritonAnnotationConversion |
将 |
triton-to-hfusion |
将Triton中的 |
TritonHistogramToHFusionConversion |
将 |
triton-to-hivm |
处理Triton的块同步操作 ( |
TritonCustomOpToHIVMSyncOpConversion |
实现Triton同步指令到HIVM同步指令的转换: |
triton-to-llvm |
将Triton中的内联汇编操作 ( |
ElementwiseInlineAsmOpConversion |
将 |
3.2.3 Ascend affinitive Operators
序号 |
Operator |
功能描述 |
|---|---|---|
1 |
tl.custom_op |
Ascend NPU扩展的自定义算子集,用于支持硬件特定的内存访问与数据搬运模式,例如: |
2 |
tl.compile_hint |
向编译器传递硬件特定的编译提示信息,用于指导后端优化策略、资源分配或内核配置。 |
3 |
tl.sync_block_wait( |
块同步等待操作。指定接收核 ( |
4 |
tl.sync_block_set( |
块同步设置操作。指定发送核 ( |
5 |
tl.sync_block_all( |
全局块同步操作。根据指定的同步模式 ( |